
PDFダイレクト翻訳 できない場合の注意点
弊社サポートでもお問い合わせの多い PDFダイレクト翻訳 。
Adobe Acrobat Proを必要とせず、元ファイルのレイアウトをできるだけ崩さぬように翻訳文を配置するこの機能は、2007年の登場以来お客様に長くご好評をいただいております。
しかしPDFで対応する形式は多岐にわたり、内部構造の複雑さ・使用フォントの多様さなどのせいで、レイアウトを保ったまま翻訳文を生成するには様々なハードルが存在します。
ここではPDFダイレクト翻訳に失敗する例、うまく翻訳できなかった場合の対処法についてご案内します。
注意:
本項目はPC-Transer V24 / Windows10環境を例に説明しています。
製品タイトルやバージョン、またOSのバージョンによって、表記や図の見栄えが異なる場合があります。
その場合は適宜読み替えてください。
1. エラーメッセージが出現し、翻訳に失敗したら
PDFファイルによっては翻訳時にエラーが出たり、途中で停止したりするケースがあります。
原因は様々ですが、多くは以下のようなエラーメッセージに大別されます。各項目の補足説明をご覧いただき、別の方法で翻訳をお試しください。
a. 「 編集保護されたファイルは開けません」
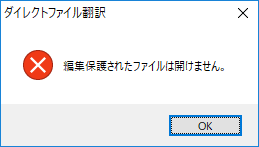 「編集保護されたファイルは開けません」 |
ファイルを開く際にパスワードを要求される(パスワード保護)PDFファイル、ファイルは開けるが編集や出力のロックがかかっている(編集保護)PDFファイルはダイレクト翻訳できません。
PDF内のテキストをコピーできる場合はⅴの翻訳エディタやワンポイント翻訳に貼り付けて翻訳する方法をお試しください。また、編集保護されたPDFファイルであればⅶの「CROSS OCR」、パスワード保護されたPDFファイルはⅵの キャプチャ翻訳で文字認識したうえで翻訳していただくこともできます。
また、2019年11月発売以降のTranserシリーズでは、PDFファイルの読み取りパスワードに対応しました。強化された「 PDFダイレクト翻訳 」の機能についてご紹介しますをご覧ください。
※権利保護されたファイルおよび文章の翻訳はできません。利用にはくれぐれもご注意ください。
b. 「テキストの格納に失敗しました」
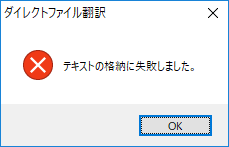 「テキストの格納に失敗しました。」 |
複雑なレイアウトを使用して作成されたファイルや、Adobe Acrobat以外のPDF作成ソフトで作られたファイルは、書類の構造やフォントの種類を解析できず、エラーとなる場合があります。
Adobe Acrobat(製品版)をお持ちでしたらⅰのAdobe Acrobatで再出力(印刷)、ⅱのAdobe AcrobatでWordファイルとして保存する、またはⅲのPDFファイルを翻訳エディタに読み込ませて翻訳するを行うことで翻訳可能になる場合があります。
また、Word2013以降をお持ちの場合はⅳのPDFファイルをWordで開くことで、「Officeアドイン翻訳」にて翻訳することができます。
c. 「翻訳対象の文字列がありません」
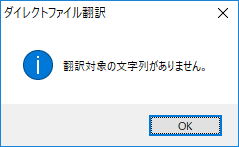 「翻訳対象の文字列がありません。」 |
文字部分が画像として保存されている(原稿をスキャナで取り込んだだけの)PDFファイルや、テキストとして認識できない図だけで構成されたPDFファイルで発生するエラーです。また、セキュリティで保護されたPDFファイルでもこのようなメッセージが出る場合があります。
このようなPDFファイルは一見すると文書のように見えますが、中身は単なる画像ファイルのため、このままでは翻訳できません。
この場合は一旦ⅶの 「CROSS OCR」を用いて文字認識させる方法で画像から文字情報を抽出し、その後に翻訳を行う必要があります。
なお、文書の一部分だけを簡単に翻訳したい場合はⅵの キャプチャ翻訳もご利用いただけます。
また、Word2013以降をお持ちの場合はⅲのPDFファイルをWordで開くことで、「Officeアドイン翻訳」にて翻訳することができる場合もあります。
2. 翻訳結果がおかしいときは
PDFダイレクト翻訳がエラーなく完了しても、作成されたファイルに問題がある場合があります。各項目の補足説明をご覧いただき、別の方法で翻訳をお試しください。
d. 元の文の上に、翻訳された文が被っていて読みづらい
 透明テキストPDFの翻訳例。原文(画像)の上に訳文(テキスト)が重なっています |
透明テキストPDFファイル(透明PDF)を翻訳した際に発生します。
透明テキストとは、スキャナが画像を読み取ると同時に文字認識した字を「透明な文として」元の原稿(画像)の上に被せたものです。
透明テキストPDFファイルを翻訳すると、元の透明文字は翻訳後に黒い文字の訳文で置き換えられ、非常に読みにくいファイルが出来上がってしまいます。
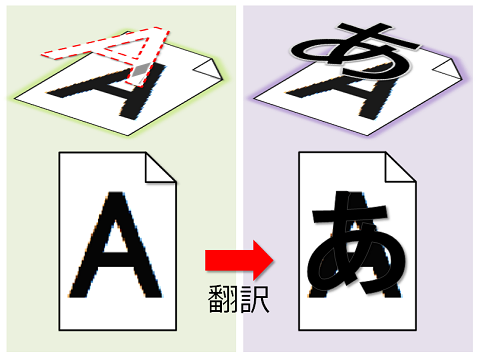 透明テキストPDFをダイレクト翻訳すると、原文の画像の上に訳文が重なって出力されてしまいます |
PDFファイルの透明テキストをコピーできる場合はは、ⅴの翻訳エディタやワンポイント翻訳に貼り付けて翻訳することができます。また、ⅶの「CROSS OCR」を用いて文字認識させる・文字を抽出することで画像からの文字認識をやり直したり、テキストのみを抽出したりして、そのうえで翻訳を行うこともできます。
e. 一部だけ翻訳されているところがあるが、ほとんど訳されていない
 ほとんど翻訳できていません |
Adobe Acrobat以外のPDF作成ソフトで作られたファイルや、海外のフォントが埋め込まれたファイルの場合、文中のスペースを認識できないことがあります。
スペースを欠いた長大な文字列は文としての解析ができないため、この部分は翻訳されず単に長い文字列として出力され、細切れになっている一部の場所だけが翻訳されたファイルが作成されます。
この場合、Adobe Acrobat(製品版)をお持ちでしたら、ⅰのAdobe Acrobatで再出力(印刷)、ⅱのAdobe AcrobatでWordファイルとして保存する、またはⅲのPDFファイルを翻訳エディタに読み込ませて翻訳するを行うことで翻訳可能になる場合があります。
また、Word2013以降をお持ちの場合はⅳのPDFファイルをWordで開くことで、「Officeアドイン翻訳」にて翻訳することができます。
また、2019年11月発売以降のTranserシリーズには「単語間の区切りを検出する」設定項目を追加しました。これにより、従来ではうまく翻訳できなかったPDFファイルでも正しく文を認識し、翻訳できるようになりました。
詳細は強化された「 PDFダイレクト翻訳 」の機能についてご紹介しますをご覧ください。
f. 翻訳後のファイルで「このページにはエラーがあります」メッセージが出現する
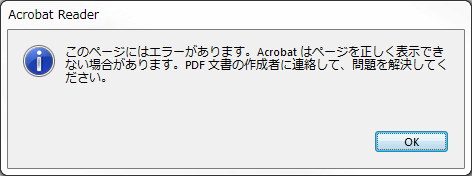 「このページにはエラーがあります。 Acrobatはページを正しく表示できない場合があります。」 |
翻訳の処理は問題なく完了しても、翻訳後のファイルを開くと上記のエラーが出現する場合があります。これもb.「テキストの格納に失敗しました」のように、Adobe標準でないPDF作成ソフトで作成されたファイルや、複雑なレイアウトを保持したファイルで発生しがちです。
この場合も、Adobe Acrobat(製品版)をお持ちでしたら、ⅰのAdobe Acrobatで再出力(印刷)、ⅱのAdobe AcrobatでWordファイルとして保存する、またはⅲのPDFファイルを翻訳エディタに読み込ませて翻訳するを行うことで翻訳可能になる場合があります。
また、Word2013以降をお持ちの場合はⅳのPDFファイルをWordで開くことで、「Officeアドイン翻訳」にて翻訳することができます。
3. 翻訳のためのヒント
ここまで、PDFファイルの翻訳がうまくいかない例をご紹介しました。しかしレイアウトが崩れてもよい、文章の概要さえ掴めればよいなどの場面でしたら、以下のような回避方法もご案内できます。このうちのどれかで解決するかもしれませんのでお試しください。
ⅰ. Adobe Acrobatで再出力(印刷)する
![AcrobatでPDFファイルを開き、 [ファイル] > [印刷] を選択します](https://www.crosslanguage.co.jp/blog/wp-content/uploads/2018/02/print_as_pdf_1.png) AcrobatでPDFファイルを開き、[ファイル] > [印刷] を選択します ![プリンターで[Adobe PDF]を選択し、[OK]をクリックしてください](https://www.crosslanguage.co.jp/blog/wp-content/uploads/2018/02/print_as_pdf_2.png) プリンターで[Adobe PDF]を選択し、[OK]を押します |
Adobe Acrobat以外のPDF作成ソフトで作られたファイルは、Adobe社純正のAcrobat(製品版)にて再度PDF出力(印刷)することで潜在的なエラーが解決し、PDFダイレクト翻訳できるようになる場合があります。
Adobe Acrobat(製品版)をお持ちの場合は、[印刷]にてPDFファイルの再出力をお試しください。
- ここでは[保存]ではなく[印刷]を選択してください。
- この手順はPDFダイレクト翻訳できるようにPDFファイルを保存する方法です。再保存後、別途翻訳を実施していただく必要があります。
- パスワード保護、編集保護などのセキュリティ保護機能が使われているPDFファイルは上記の方法でも翻訳できるようにならない場合があります(a.「編集保護されたファイルは開けません」参照)。
- 再保存したPDFファイルでも翻訳に失敗する、フォントが文字化けする等、期待した翻訳結果が得られない場合があります。そのときはⅱ. のAdobe AcrobatでWordファイルとして保存する以降をお試しください。
ⅱ. Adobe AcrobatでWordファイルとして保存する
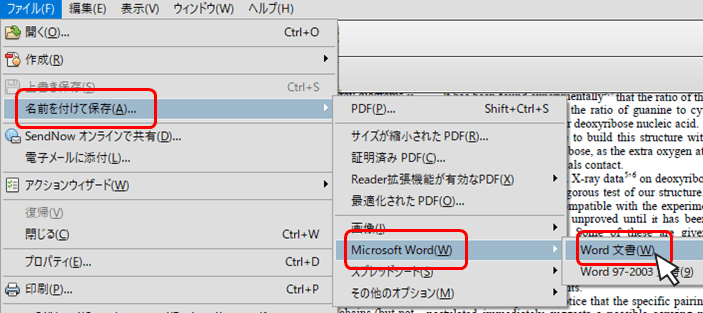 Adobe AcrobatでWordファイルとして保存します |
Adobe Acrobat(製品版)では、PDFファイルをWordファイルに変換して保存することができます。エラーが出るPDFファイルでも、Wordファイルとして保存できさえすれば「Officeアドイン翻訳」にて翻訳することが可能です。またTranserシリーズの場合は、Officeファイルを直接翻訳エディタに読み込んで翻訳し、レイアウトを保ったまま出力する機能があります。
この方法はⅰ. のAdobe Acrobatで再出力(印刷)する方法と比較するとレイアウトは保持されづらい傾向にありますが、Officeアドイン翻訳はエラーが少なく、確かな出力が期待できます。
- この手順はPDFファイルを別形式で保存しなおす方法です。再保存後、別途翻訳を実施していただく必要があります。
- Officeアドイン翻訳については、翻訳エディタの [ヘルプ] > [ユーザーズ・ガイド] を参照し、「Microsoft Officeアドイン翻訳」の項目をご覧ください。
- TranserシリーズにてOfficeファイルを直接翻訳エディタに読み込む方法については、[ユーザーズ・ガイド]の「文書の入出力」の項目をご覧ください。なお、この機能は翻訳ピカイチシリーズには非搭載です。
- パスワード保護、編集保護などのセキュリティ保護機能が使われているPDFファイルはWordファイルとして保存できない場合があります(a.「編集保護されたファイルは開けません」参照)。この場合はPDFファイルの作成元にお問い合わせいただくか、ⅴ. のテキストをコピーし、翻訳エディタやワンポイント翻訳に貼り付けて翻訳する以降をお試しください。
ⅲ. PDFファイルを翻訳エディタに読み込ませて翻訳する
翻訳エディタの [ファイル] > [開く] にて、PDFファイルを開くことができます。
読み込んだ文章は適宜翻訳を行っていただき、翻訳ファイルやテキストファイルで保存することが可能です。
- この手順はPDFファイルを翻訳エディタで開く方法です。開いた後、別途翻訳を実施していただく必要があります。
- PDFファイルを翻訳エディタで開いた場合、テキストや翻訳ファイルとしての保存が可能です。ふたたびPDFファイルとして保存することはできませんのでご注意ください。
ⅳ. PDFファイルをWordで開き、Wordファイルとして保存する
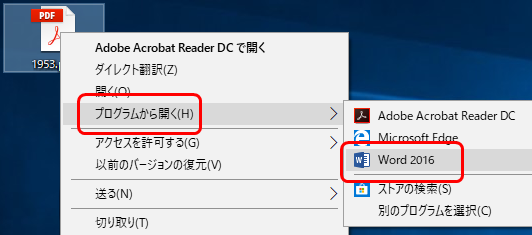 PDFファイルを右クリックし、Wordで開く例 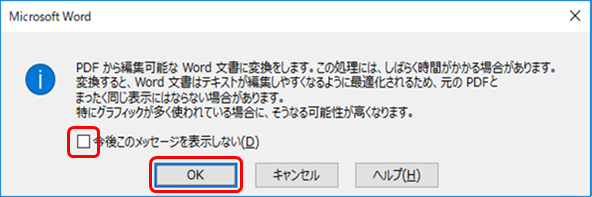 PDFをWordファイルに変換する際、アラートが出ます 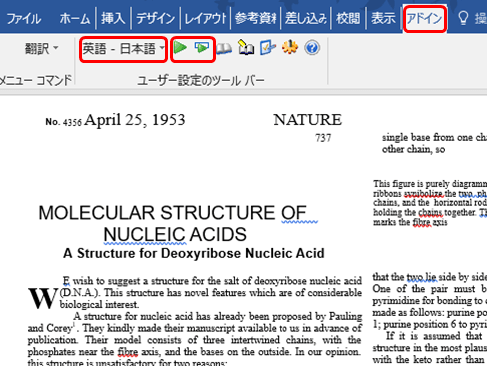 Wordで開くことでOfficeダイレクト翻訳がご利用いただけます |
Microsoft Word(2013以降)をお持ちの場合は、PDFファイルをWord文書として開くことが可能です。
開きさえすれば、ⅱ. のAdobe AcrobatでWordファイルとして保存するのように「Officeアドイン翻訳」にて翻訳することができます。
- この手順はPDFファイルをWordで開く方法です。開いた後、別途翻訳を実施していただく必要があります。
- Officeアドイン翻訳については、翻訳エディタの [ヘルプ] > [ユーザーズ・ガイド] を参照し、「Microsoft Officeアドイン翻訳」の項目をご覧ください。
- TranserシリーズにてOfficeファイルを直接翻訳エディタに読み込んで翻訳する方法については、[ユーザーズ・ガイド]の「文書の入出力」の項目をご覧ください。なお、この機能は翻訳ピカイチシリーズには非搭載です。
- パスワード保護、編集保護などのセキュリティ保護機能が使われているPDFファイルは上記の方法で開けない場合があります(a.「編集保護されたファイルは開けません」参照)。この場合はPDFファイルの作成元にお問い合わせいただくか、ⅴ. のテキストをコピーし、翻訳エディタやワンポイント翻訳に貼り付けて翻訳する以降をお試しください。
ⅴ. テキストをコピーし、翻訳エディタやワンポイント翻訳に貼り付けて翻訳する
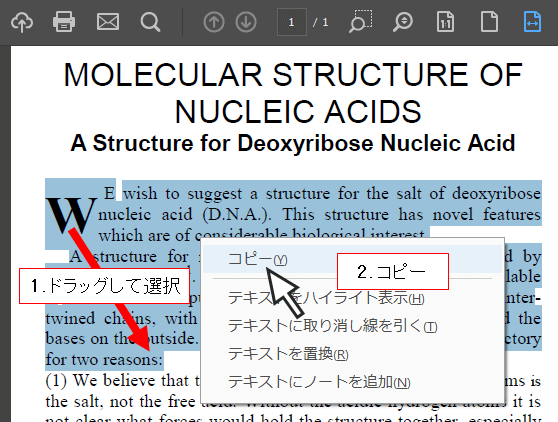 PDF文書内でドラッグし、テキストをコピー 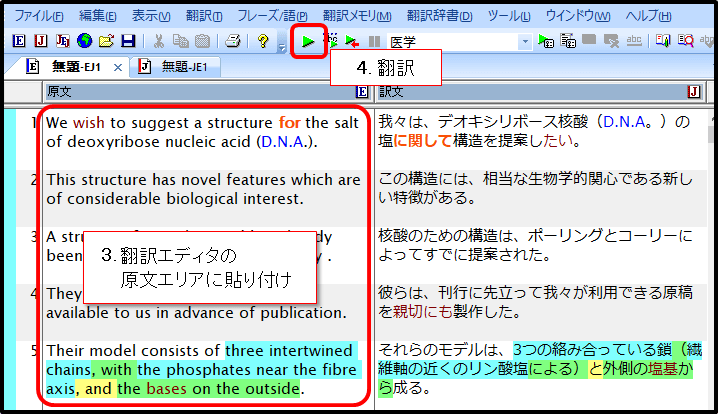 翻訳エディタに貼りつけ、翻訳してください ![翻訳パレットより[ワンポイント翻訳]を起動して・・・](https://www.crosslanguage.co.jp/blog/wp-content/uploads/2018/02/onepoint_tran_1.png) または、翻訳パレットより[ワンポイント翻訳]を開いて・・・ 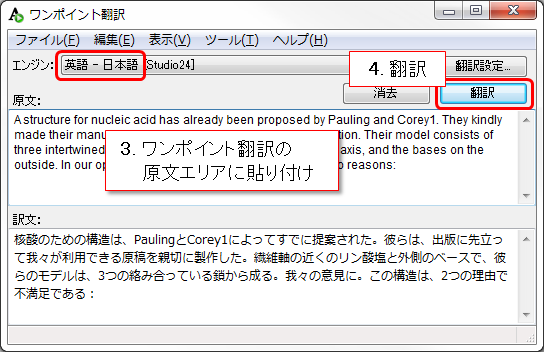 原文を貼り付けて簡単に翻訳することもできます |
PDFファイル内のテキストを選択してコピーできる場合は、コピーしたテキストを翻訳エディタやワンポイント翻訳に貼りつけて翻訳することができます。元のPDFからテキストだけを抜き出すためレイアウトは保持できませんが、文章の内容を掴むことはできます。透明テキストPDFの場合にはこの方法が有効です。
ⅵ. キャプチャ翻訳を使用する
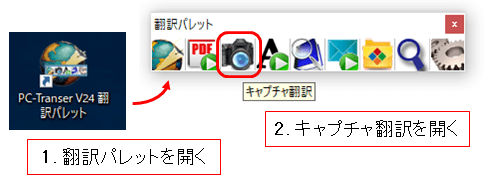 翻訳パレットより「キャプチャ翻訳」を開いて・・・  認識・翻訳したい範囲を選択、翻訳できます |
PDFファイルの全ページを一度に翻訳することはできませんが、パソコンの画面をキャプチャして翻訳を行う「キャプチャ翻訳」の機能もお試しください。画像だけのPDFファイル、セキュリティ保護でWordへの変換やテキストのコピーができないPDFファイルに有効です。
- キャプチャした画像内の文字が以下のような場合は、文字認識処理が正しくできない場合があります。
● 文字の背景に模様や影、ノイズなどがある
● 文字と背景色が識別しにくい
● 認識対象の画像文字の文字サイズが小さい
● 斜体、筆文字、ポップ文字などのデザインされたフォントで表現された文字
(基本の認識対応書体は、明朝系/ゴシック系です)
また、本機能は著作権を侵害する行為等にはご利用になれません。 - キャプチャ翻訳については、翻訳エディタの [ヘルプ] > [ユーザーズ・ガイド] を参照し、「翻訳パレット-キャプチャ翻訳」の項目をご覧ください。
ⅶ. 画像PDFを文字認識ソフト「CROSS OCR」で認識させる
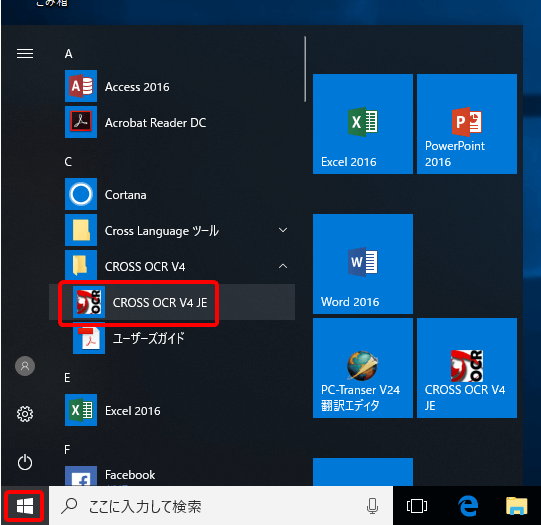 スタートメニューからCROSS OCRを開きます 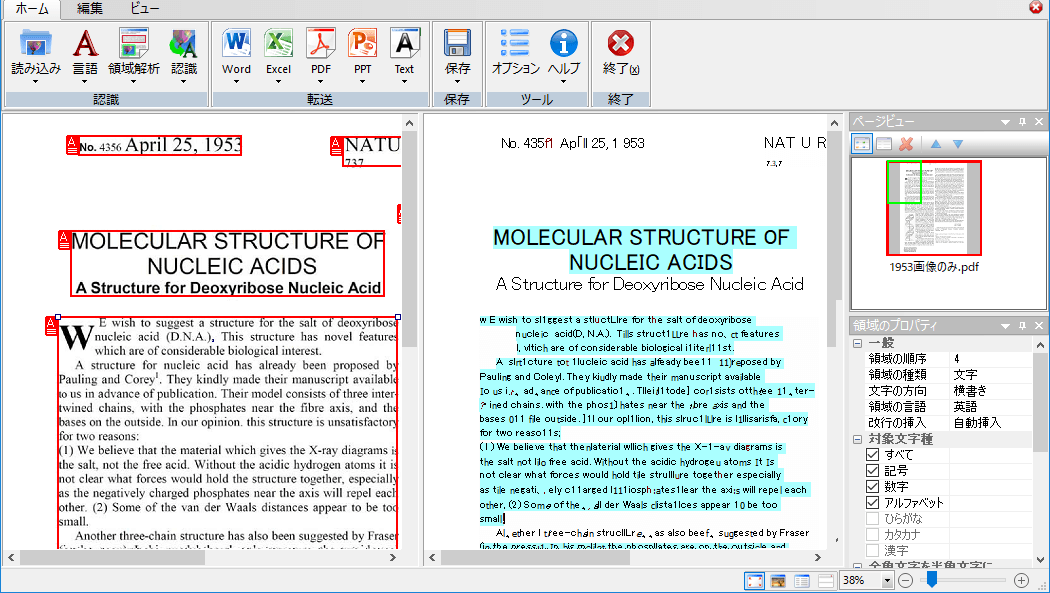 画像PDFをCROSS OCRで読み込み、文字認識させます |
スキャンしただけのPDF(画像PDF)は、文字認識ソフト「CROSS OCR」を使用して各ページの画像を読み込み、文字として認識させることができます。また、セキュリティ保護のためにWordへの変換やテキストのコピーができないPDFファイルにも有効です。
また、透明テキストPDFファイル(透明PDF)ファイルであれば、PDFファイル内のテキスト情報だけを抽出して別途保存することが可能です。
- この手順は文字認識ソフト「CROSS OCR」を用いて文字認識や文字抽出を行うする方法です。本ソフトウェアで文字を処理した後、別途翻訳を行う必要があります。
- 弊社ソフトウェアのインストール時に、一緒にCROSS OCRをインストールしている必要があります。
- CROSS OCRの詳細な使用方法については、「CROSS OCR ユーザーズ・ガイド」をご覧ください。
4. まとめ
PDFダイレクト翻訳できない、結果がおかしい場合におすすめする対処法を紹介しました。
まとめると、以下のとおりになります。
- PDFダイレクト翻訳に失敗するファイルは、Adobe Acrobat(製品版)をお持ちの場合は再出力(印刷)することでダイレクト翻訳できるようになるかもしれません。
- Adobe Acrobat(製品版)にてWordファイル(.docx)として保存できれば、Officeアドイン翻訳をご利用いただけるほか、翻訳エディタに読み込んでの処理が可能となります。
- 翻訳エディタでPDFファイルを読み込むことができます。ふたたびPDFファイルとして保存することはできませんが、翻訳エディタの機能を用いた柔軟な翻訳が可能となります。
- Word2013以降ではWordにてPDFファイルを開く機能があります。Wordで開くことができればOfficeアドイン翻訳をご利用いただけます。
- Transerシリーズでは、Wordファイルを翻訳エディタに読み込ませて翻訳を実施する機能があります。
- 文字が重なってしまう症状のファイル(透明テキストPDF)はテキストをコピーして別途翻訳するか、CROSS OCRで文字認識をやり直したうえで別途翻訳を実施してください。
- 画像だけのPDFファイルはキャプチャ翻訳で手軽に文字認識・翻訳するか、CROSS OCRで文字認識をやり直したうえで別途翻訳を実施してください。
- セキュリティ保護されたPDFファイルではキャプチャ翻訳が有効です。
ただし、やはりどうしても翻訳できないファイルもあるため、PDFダイレクト翻訳については以下のように制限事項を設けております。
(ユーザーズガイド「PDFダイレクトファイル翻訳の制限事項」をご覧ください)
|
PDFダイレクトファイル翻訳は、原文のPDFファイルからテキストを抽出し、翻訳結果のPDFファイルを作成します。翻訳結果ではフォントの種類、サイズ、レイアウトなどを原文と同様に配置します。 ■ 以下の場合は翻訳できないことがあります。
■ 以下の場合はレイアウトが保てないことがあります。
PDFファイルがうまく翻訳できない場合は、Adobe AcrobatまたはAcrobat ReaderでPDFを開いてテキストをコピーして、翻訳エディタの原文エリアにテキストを貼り付けて翻訳を行ってください。 Adobe Acrobatをお持ちの場合、Adobe Acrobatで開いて、[印刷]からAdobe Acrobatを選択し、PDFに再保存することで、翻訳可能なPDFにできる場合があります。 ■ 文字が画像データであるPDFファイルは翻訳できません。 ■ 透明テキストデータであるPDFファイルは、画像の上にテキスト文が表示されます。 |
内容についてご不明な点がございましたら、こちらのお問い合わせフォームにてお問い合わせください。

