※この記事は15分で読めます。
翻訳メモリ とは、原文と訳文のセットをデータベースに登録しておき、 次に似たような文が出現したときに文章の骨格を使いまわすことで効率的に翻訳することができるようにする機能です。
単語を辞書引きして訳文を作るように、「典型的な文にはサンプルとなる訳文を用意しておこう」また「さっき翻訳した言い回しはよく出てくるので次に役立てよう」という、いわば”文章を登録するユーザー辞書”の機能と考えることもできます。
翻訳メモリ機能は効率的な翻訳業務を強力に支援する、Transerシリーズの重要な機能です。たいへん便利な機能ですが、サポートでお客様にお伺いすると「機能は知っているがよくわからない」とのお声をいただくことがあります。
本エントリではPC-Transer V24を例に、翻訳メモリの原理に重点を置き、基本的な登録方法・使用方法をご紹介します。この機会にぜひ活用してみてください。
※ 翻訳メモリはTranserシリーズ(Professional)および翻訳ブレインの機能です。翻訳ピカイチおよびTranserシリーズ(Personal)、明解翻訳ではご利用いただけません。
1. 翻訳辞書と翻訳メモリ
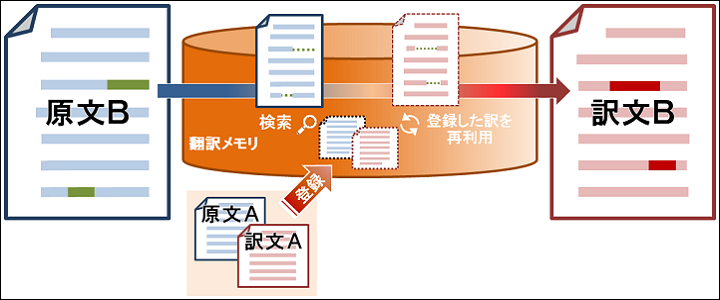
翻訳辞書が「単語・熟語と、それに対する訳語」のデータベースであるのに対し、翻訳メモリは「原文とその訳文」、つまり対訳文のデータベースです。
豊富な翻訳辞書は正確な訳を導く助けとなり、適切な辞書登録は次の翻訳においてより適切な訳語を提供します。翻訳メモリも同様ですが、翻訳辞書と違うのは「単語や熟語」単位ではなく「文章や句(フレーズ)」を扱うという点です。
PC-Transerの翻訳メモリは、登録した文をそのまま再利用する「完全一致文検索」、訳の参考として似たような文を検索する「類似文検索」に加え、文中で変化する箇所を指定して似たような文の骨格を使いまわせる「文型一致文検索」、登録された文との差異が少ない場合は変化している箇所を自動的に認識して訳文を生成する「自動文型一致文検索」を備えています。
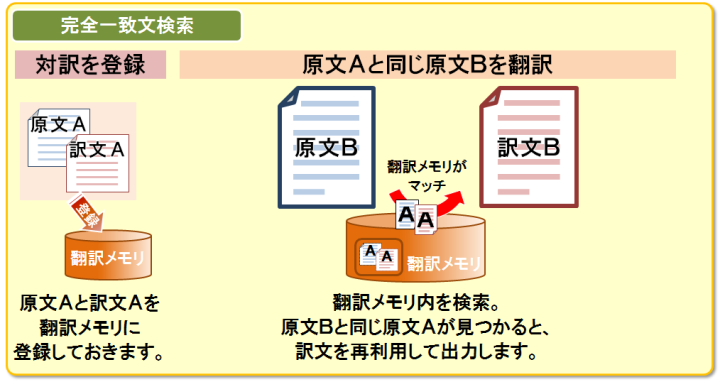
完全一致文検索。登録した文と同じ文を翻訳する際には、以前の訳文を再利用します
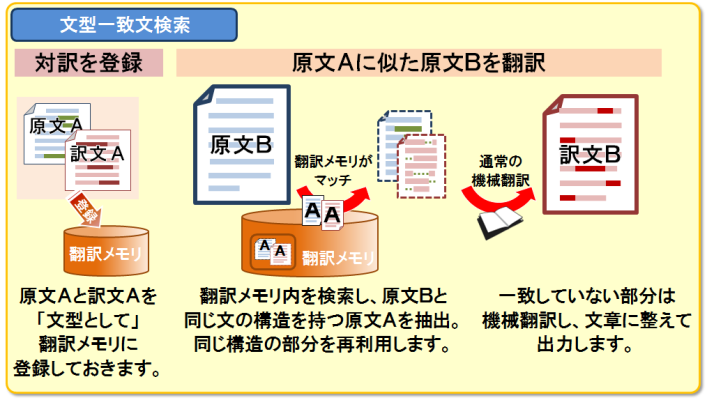
文型一致文検索。頻出する文の骨格を「文型」として登録しておくことで、文中でわずかに変化する箇所を認識し、文の骨格を再利用するとともに、差異のある部分は機械翻訳して出力します
特に取扱説明書・法務文・特許文・マニュアルなど、文中の数字や名詞が変わるだけで基本的に同じような言い回しや表現が使われるビジネス文書を翻訳する際には、そのような定型文や似たような表現の訳文を登録して再利用できれば、その後の翻訳効率が飛躍的に向上することでしょう。翻訳メモリを使い始めて最初のうちはなかなか効果を実感できないかもしれませんが、登録してゆくうちにその後の翻訳での適用範囲が広がってゆき、使い込むほどに効率が向上してゆくことを実感していただけるはずです。
2. 翻訳メモリを登録してみる
翻訳メモリ機能は「よく使われがちな文を登録し、次に使いまわす」ことで本領を発揮します。
英文の手順書にありがちな翻訳を例に、実際に翻訳メモリに登録する例をご覧ください。
まずは登録したい文をそのまま翻訳してみます。
<例1>
原文A:
Add 10g of glucose to the thawed sample and stir it at 37 degrees for 30 minutes and subject it to autoclave.
翻訳メモリを使わず機械翻訳した訳文:
10gのブドウ糖を解凍されたサンプルに加えて、37度で30分の間それをかき回して、それにオートクレーブを受けさせる。
このままでも一応意味は通じますが、手順書にふさわしい文体になるよう手直しして、原文Aの訳文として翻訳メモリに登録します。
原文A:
Add 10g of glucose to the thawed sample and stir it at 37 degrees for 30 minutes and subject it to autoclave.
原文Aに対する訳として、翻訳メモリに登録する対訳文(訳文A):
解凍した試料にブドウ糖を10g加え、37℃・30分間撹拌したのちオートクレーブする。
翻訳メモリに登録してから原文Aを再翻訳すると、先ほど翻訳メモリに登録したとおりの訳文が出力され、訳文は翻訳メモリが使用されたことを示す黄色で表示されます。今後、同じ文章や似た文章を翻訳する際には、この翻訳メモリが参考になります。
一連の動作は動画でもご覧いただけます(クリックで拡大します)。
3. 翻訳メモリの基本的な動作原理
翻訳を開始すると、PC-Transerは最初に原文が翻訳メモリに存在しているかどうかを検索し、見つかった場合はそれに対する訳文を返します。見つからなかった場合は通常の機械翻訳(文を要素に分解し、単語やフレーズごとに細かく翻訳)を行います。翻訳メモリの使用は設定でON/OFFできるので、実際の訳出の変化をご覧いただくことができます。
このように翻訳メモリは文法を意識した通常の機械翻訳の動きとは異なり、ことわざや定型句など、文の構造や要素を無視した訳文が期待される場面で力を発揮します。
PC-Transerにはあらかじめ、日本語・英語の両方で使用される定型文やことわざが「システム翻訳メモリ」として多数登録されています。以下の例をご覧ください。
原文:
済んでしまったことは取り返しがつかない。
システム翻訳メモリを使用した訳文:
What is done cannot be undone.
翻訳メモリを使用せずに機械翻訳した訳文:
It is irreparable to have finished.
以下は、同じ文を従来の翻訳エンジンと翻訳メモリで訳し分けるときの挙動を図示したものです。通常の機械翻訳では文の要素を解析して翻訳するのに対し、翻訳メモリは登録されている原文に対応する訳文をそのまま出力します。
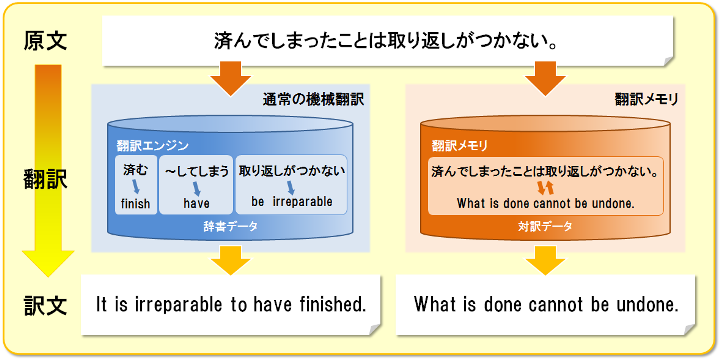
通常の機械翻訳と翻訳メモリによる翻訳の違い。翻訳メモリによる翻訳では文の解析や辞書引きは行わず、原文に対する訳文を返します
上記の例文の場合、システム翻訳メモリのデータベースには英文と日本文のセットとして以下のようなかたちで登録されています。
<翻訳メモリの登録内容>
日本文:
済んでしまったことは取り返しがつかない。
英文:
What is done cannot be undone.
システム翻訳メモリは上記のような定型句の翻訳が得意ですが、文章の様式は人や場面で多種多様なため、ことわざや定型句を除くとシステム翻訳メモリ自体が翻訳時に使用される場面はそれほど多くないと思われます。システム翻訳メモリはあくまで「表現例文集」のようなものとして、次回以降で紹介する「キーワード検索」や、訳例の検索に使用していただくと便利です。
翻訳メモリの真価は、好みの文を自分で登録して再利用する「ユーザー翻訳メモリ」を使用することで実感いただけます。次回の記事では、先ほど登録したユーザー翻訳メモリを、似たような別の文の翻訳に役立てる例をご覧いただきます。
(「翻訳メモリの使い方 2. 似たような文を翻訳してみよう」 に続きます)
4. 補足
PC-Transerでは、普段は翻訳メモリの使用が優先され、翻訳メモリの検索に合致しない場合に通常の機械翻訳が使用されます。ただし、以下の方法で通常の機械翻訳を使用することが可能です。
![方法1: [翻訳]>[翻訳設定]>[翻訳]>[訳文生成方法]にて 「機械翻訳」以外のチェックを全て外します](https://www.crosslanguage.co.jp/blog/wp-content/uploads/2018/07/tran_mem_off-1.png)
方法1: [翻訳]>[翻訳設定]>[翻訳]>[訳文生成方法]にて
「機械翻訳」以外のチェックを全て外します
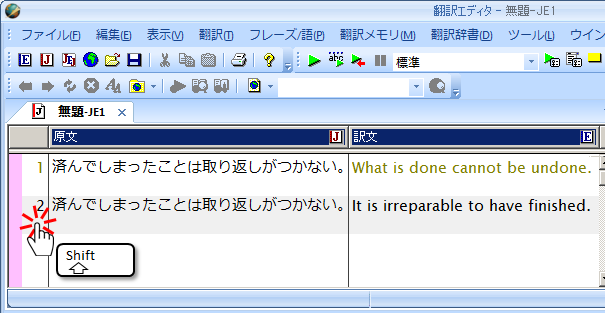
方法2:Shiftキーを押しながら文番号エリアをクリックします
内容についてご不明な点がございましたら、こちらのお問い合わせフォームにてお問い合わせください。